|
P40 hdfs产生背景和定义

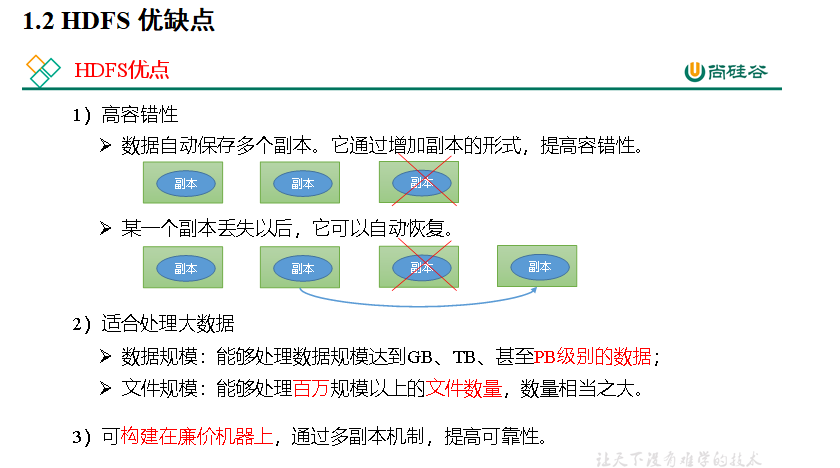
p41 优缺点
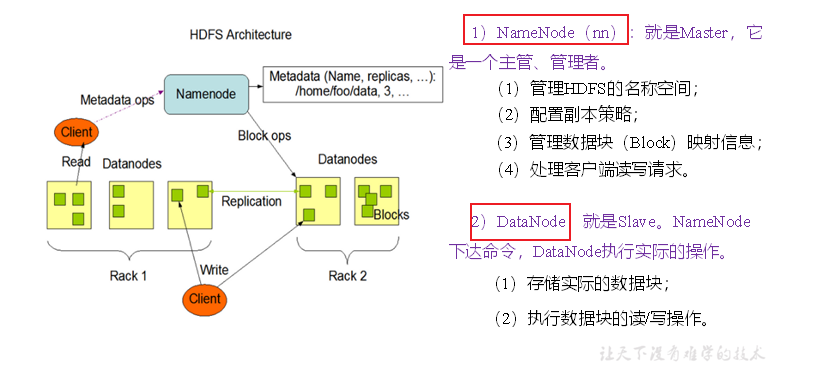
p42 组成
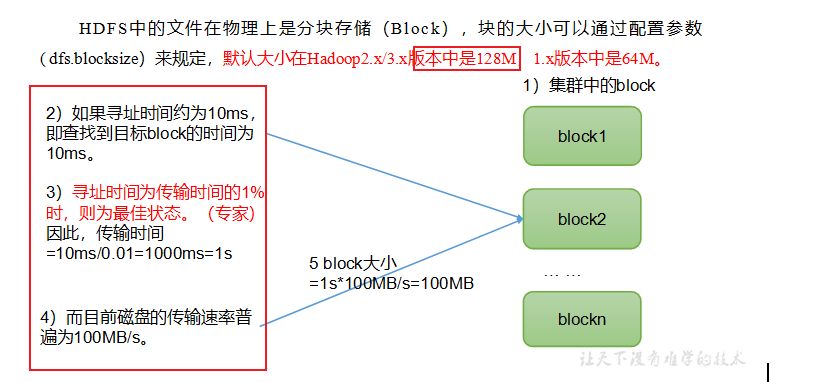
p43 文件块大小
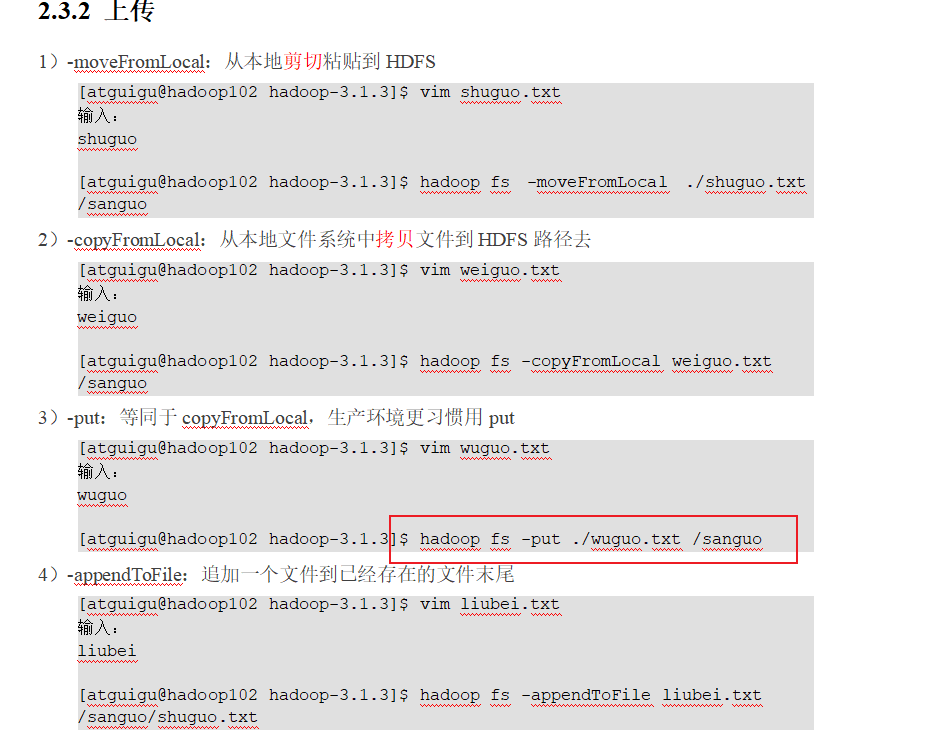
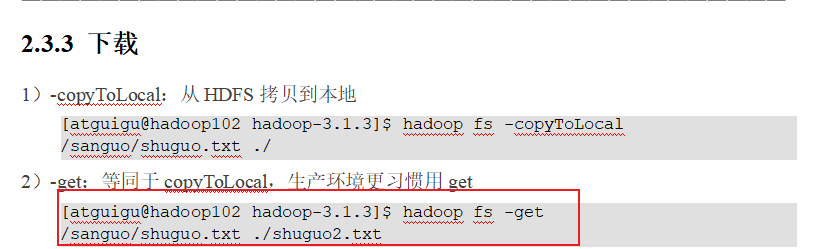
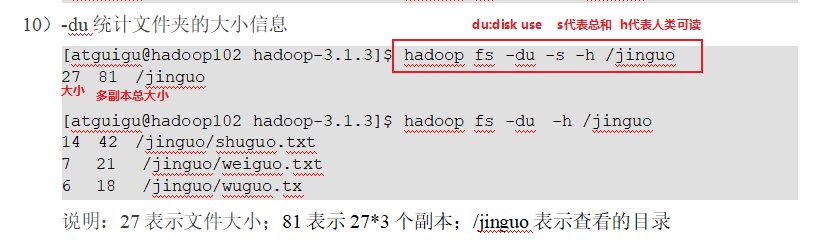
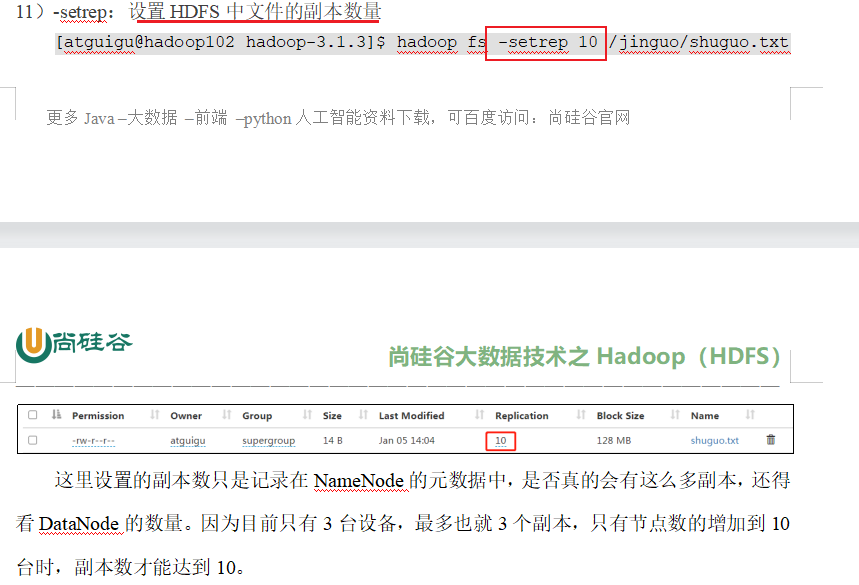
p 44 45 shell命令
p46 api环境准备
  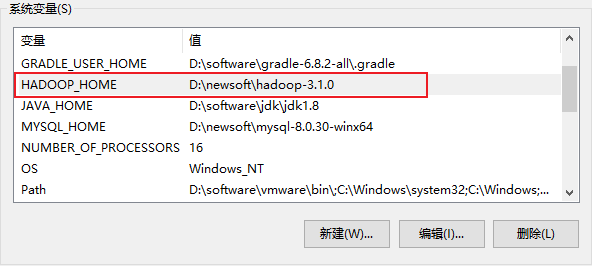
p47 api创建文件夹
新建maven项目 pom.xml
org.apache.hadoop
hadoop-client
3.1.3
junit
junit
4.12
org.slf4j
slf4j-log4j12
1.7.30
log4j.properties
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
public class HdfsClient {
FileSystem fileSystem;
@Before
public void before() throws URISyntaxException, IOException, InterruptedException{
Configuration config = new Configuration();
URI uri = new URI("hdfs://xiaoxiong02:8020");
fileSystem = FileSystem.get(uri, config, "atguigu");
}
@Test
public void testMkdirs() throws IOException {
fileSystem.mkdirs(new Path("/xiyou/huaguoshan1"));
}
@After
public void after() throws IOException{
fileSystem.close();
}
}
p48 api上传
@Test
public void upload() throws IOException {
fileSystem.copyFromLocalFile(false,false,new Path("D:\\sunwukong.txt"),new Path("/xiyou/huaguoshan"));
}
p49 api参数优先级设置
参数优先级排序:(1)客户端代码中设置的值 >(2)ClassPath下的用户自定义配置文件 >(3)然后是服务器的自定义配置(xxx-site.xml) >(4)服务器的默认配置(xxx-default.xml)
Configuration config = new Configuration();
config.set("dfs.replication", "2");
配置文件中配置 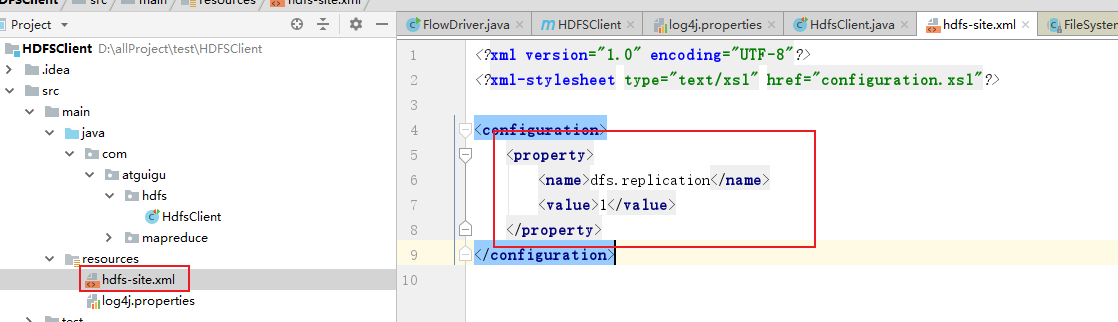
p50 api 文件下载
@Test
public void download() throws IOException {
fileSystem.copyToLocalFile(false,new Path("/xiyou/huaguoshan/"),new Path("D:\\"),true);
}
p51 删除目录
@Test
public void delete() throws IOException {
fileSystem.delete(new Path("/xiyou/huaguoshan/"),true);
}
p52 文件更名和移动
@Test
public void rename() throws IOException {
// fileSystem.rename(new Path("/0528/test1.txt"),new Path("/0528/test2.txt"));
fileSystem.rename(new Path("/0528/test2.txt"),new Path("/0529/"));
}
p53 文件详情查看
@Test
public void detail() throws IOException {
RemoteIterator iterator = fileSystem.listFiles(new Path("/"), true);
while (iterator.hasNext()){
LocatedFileStatus fileStatus = iterator.next();
System.out.println("========" + fileStatus.getPath() + "=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}

p54 文件和目录判断
@Test
public void listStatus() throws IOException {
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/"));
for (FileStatus fileStatus : fileStatuses) {
if (fileStatus.isDirectory()){
System.out.println("目录:"+fileStatus.getPath().getName());
}else {
System.out.println("文件:"+fileStatus.getPath().getName());
}
}
}
p55 写数据流程
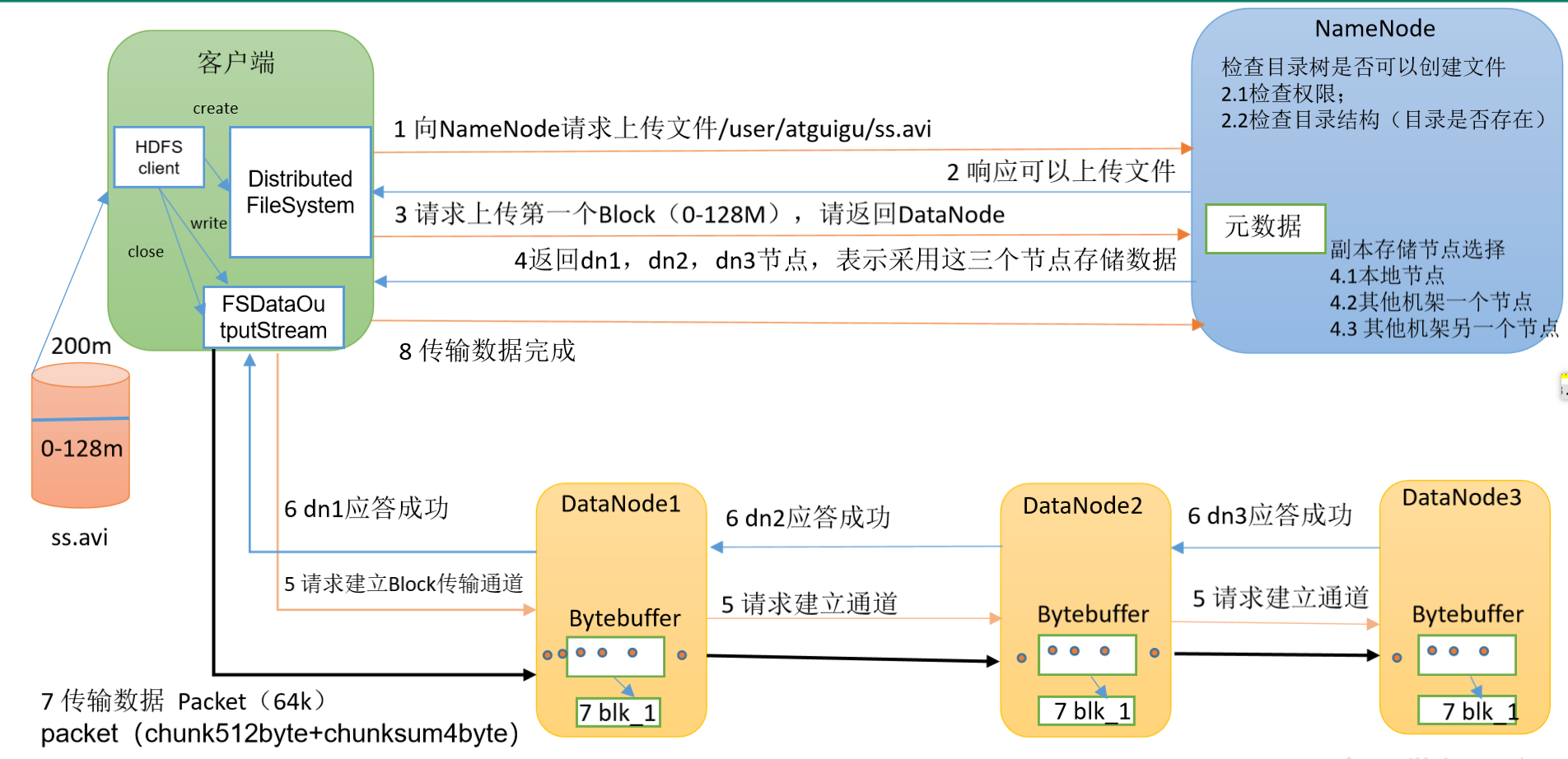 (1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。 (2)NameNode返回是否可以上传。 (3)客户端请求第一个 Block上传到哪几个DataNode服务器上。 (4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。 (5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。 (6)dn1、dn2、dn3逐级应答客户端。 (7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。 (8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。 (1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。 (2)NameNode返回是否可以上传。 (3)客户端请求第一个 Block上传到哪几个DataNode服务器上。 (4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。 (5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。 (6)dn1、dn2、dn3逐级应答客户端。 (7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。 (8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
p56 节点距离计算
在HDFS写数据的过程中,NameNode会选择距离待上传数据最近距离的DataNode接收数据。那么这个最近距离怎么计算呢? 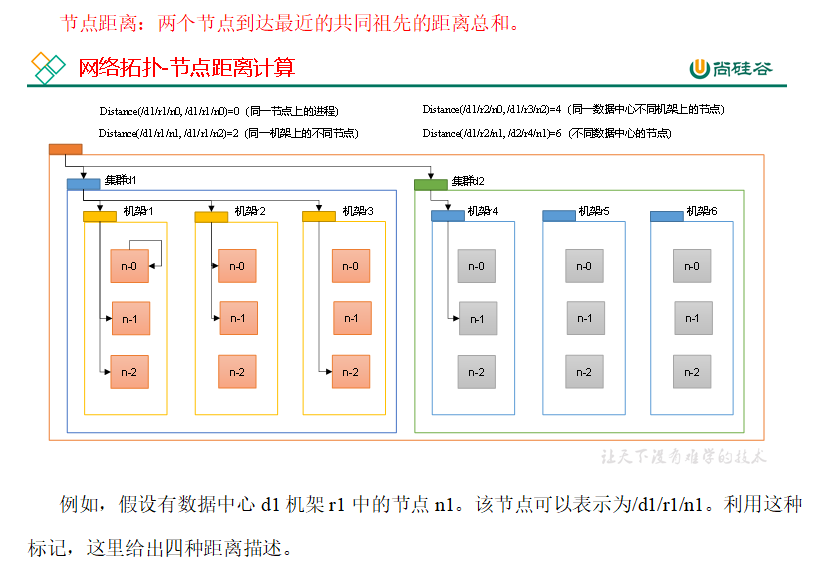 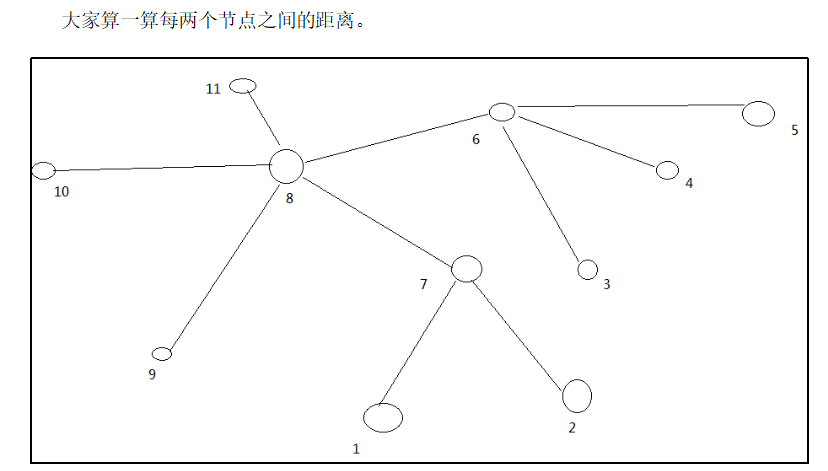
p57机架感知
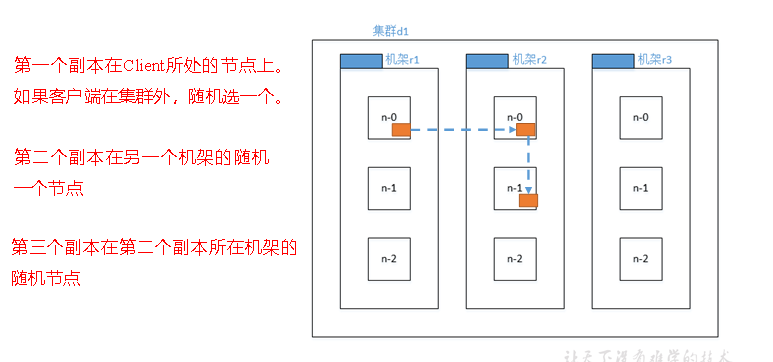
p58 读数据流程
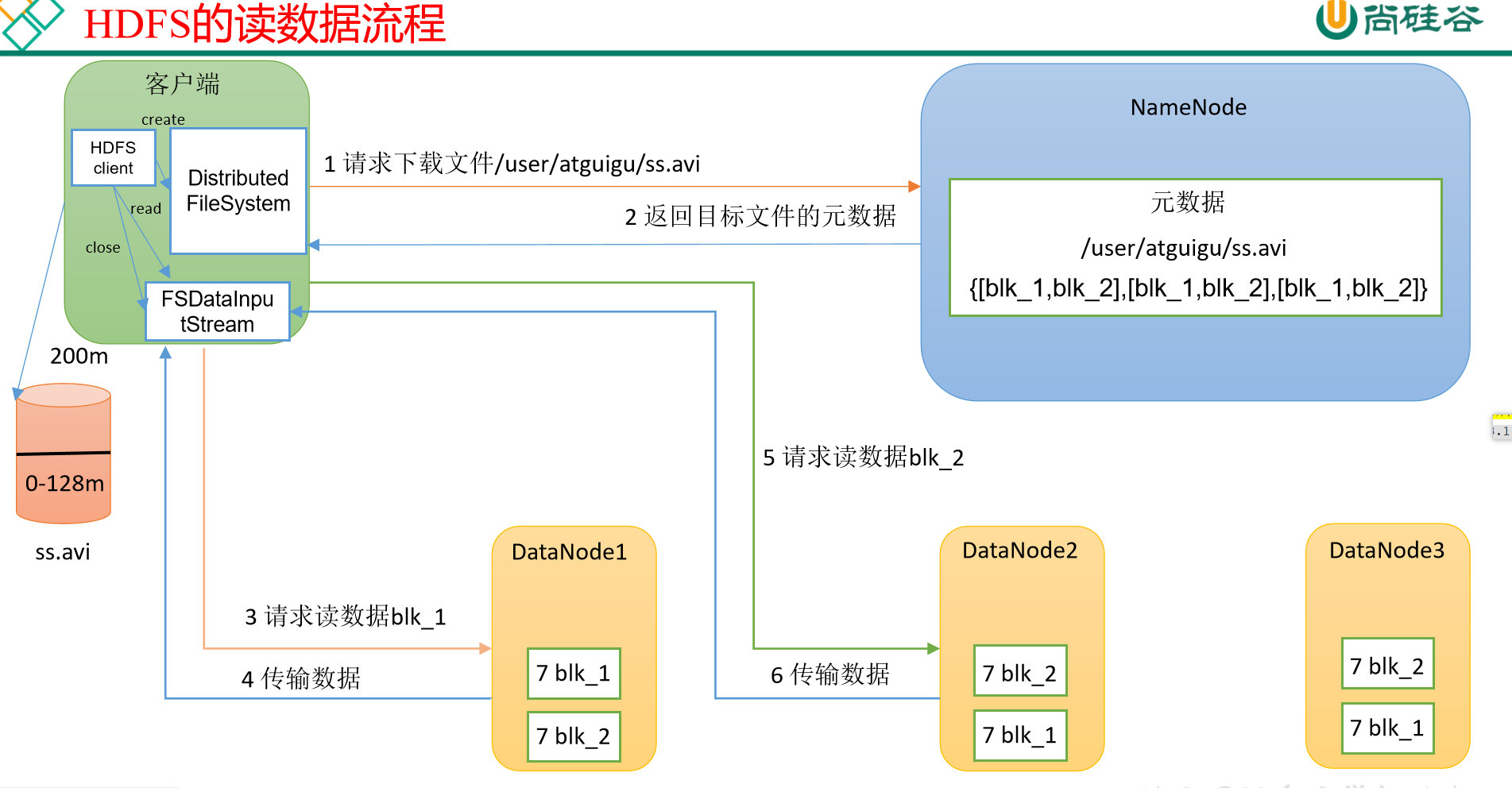 (1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。 (2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。 (3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。 (4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。 (1)客户端通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址。 (2)挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。 (3)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。 (4)客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
p59 NN和2NN工作机制
思考:NameNode中的元数据是存储在哪里的? 首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。 这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。 但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。 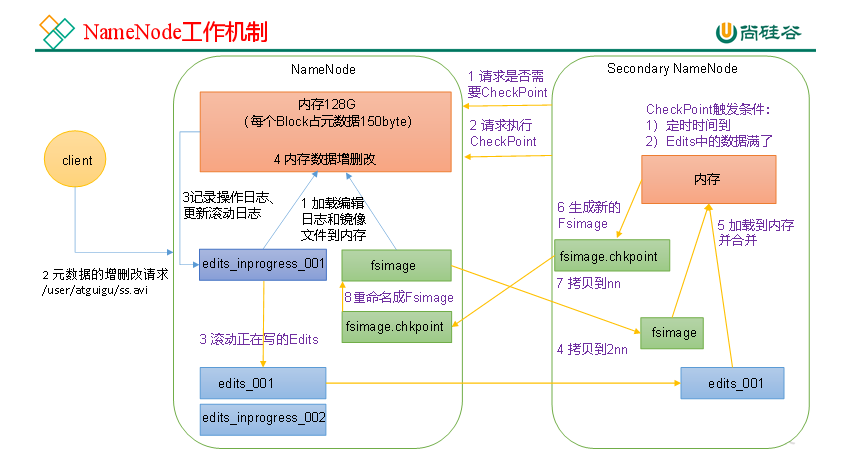 第一阶段:NameNode启动 (1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。 (2)客户端对元数据进行增删改的请求。 (3)NameNode记录操作日志,更新滚动日志。 (4)NameNode在内存中对元数据进行增删改。 2)第二阶段:Secondary NameNode工作 (1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。 (2)Secondary NameNode请求执行CheckPoint。 (3)NameNode滚动正在写的Edits日志。 (4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。 (5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。 (6)生成新的镜像文件fsimage.chkpoint。 (7)拷贝fsimage.chkpoint到NameNode。 (8)NameNode将fsimage.chkpoint重新命名成fsimage。 第一阶段:NameNode启动 (1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。 (2)客户端对元数据进行增删改的请求。 (3)NameNode记录操作日志,更新滚动日志。 (4)NameNode在内存中对元数据进行增删改。 2)第二阶段:Secondary NameNode工作 (1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。 (2)Secondary NameNode请求执行CheckPoint。 (3)NameNode滚动正在写的Edits日志。 (4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。 (5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。 (6)生成新的镜像文件fsimage.chkpoint。 (7)拷贝fsimage.chkpoint到NameNode。 (8)NameNode将fsimage.chkpoint重新命名成fsimage。
p60 fsimage镜像文件
 oiv查看Fsimage文件 oiv查看Fsimage文件 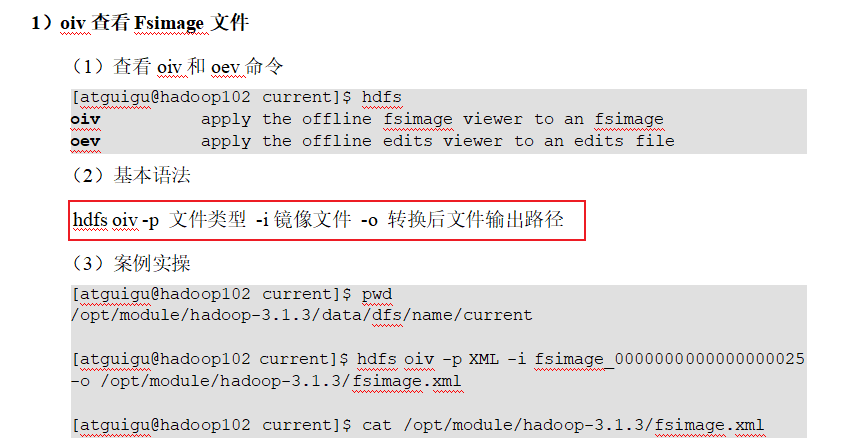
16386
DIRECTORY
user
1512722284477
atguigu:supergroup:rwxr-xr-x
-1
-1
16387
DIRECTORY
atguigu
1512790549080
atguigu:supergroup:rwxr-xr-x
-1
-1
16389
FILE
wc.input
3
1512722322219
1512722321610
134217728
atguigu:supergroup:rw-r--r--
1073741825
1001
59
思考:可以看出,Fsimage中没有记录块所对应DataNode,为什么? 在集群启动后,要求DataNode上报数据块信息,并间隔一段时间后再次上报。
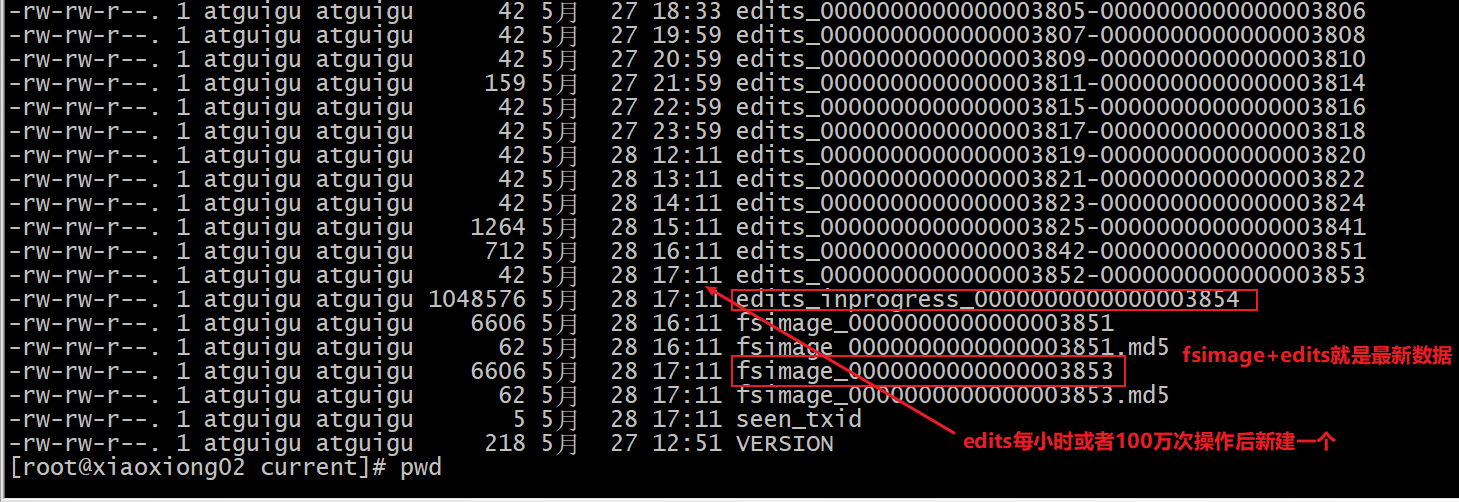
p61 edits编辑日志
基本语法 hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径

-63
OP_START_LOG_SEGMENT
129
OP_ADD
130
0
16407
/hello7.txt
2
1512943607866
1512943607866
134217728
DFSClient_NONMAPREDUCE_-1544295051_1
192.168.10.102
true
atguigu
supergroup
420
908eafd4-9aec-4288-96f1-e8011d181561
0
OP_ALLOCATE_BLOCK_ID
131
1073741839
OP_SET_GENSTAMP_V2
132
1016
OP_ADD_BLOCK
133
/hello7.txt
1073741839
0
1016
-2
OP_CLOSE
134
0
0
/hello7.txt
2
1512943608761
1512943607866
134217728
false
1073741839
25
1016
atguigu
supergroup
420
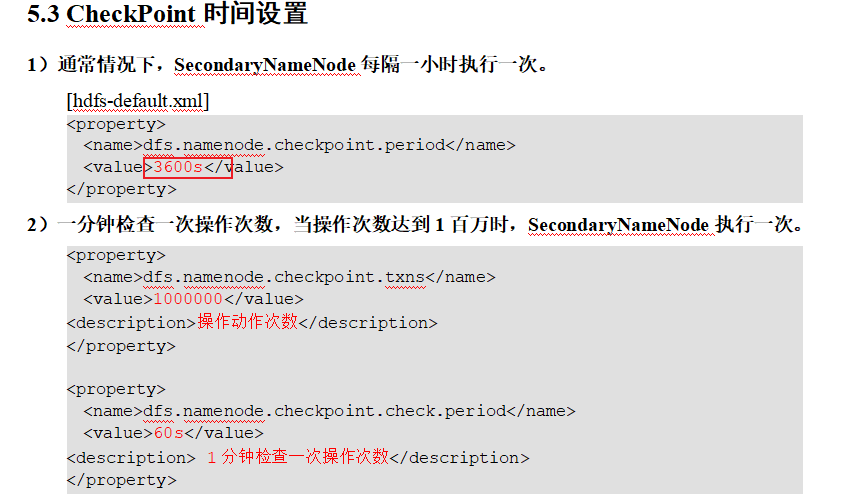
p62 检查点时间checkpoint设置
p63 datanode工作机制
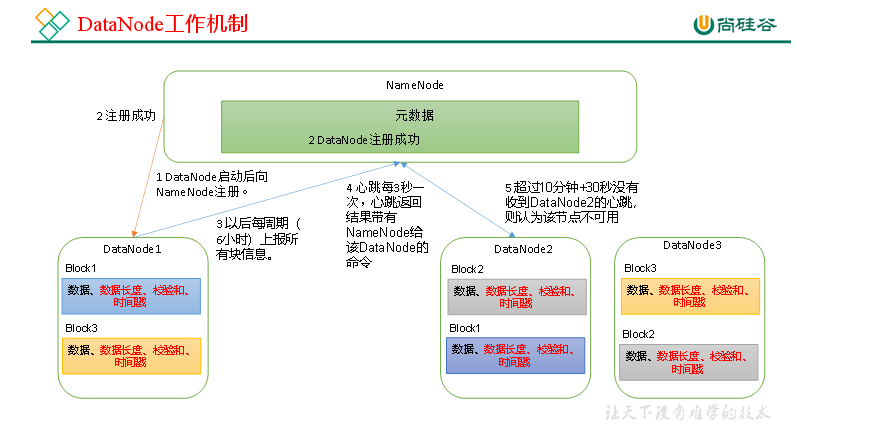 (1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。 (2)DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息。 DN向NN汇报当前解读信息的时间间隔,默认6小时; (3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。 (4)集群运行中可以安全加入和退出一些机器。 (1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。 (2)DataNode启动后向NameNode注册,通过后,周期性(6小时)的向NameNode上报所有的块信息。 DN向NN汇报当前解读信息的时间间隔,默认6小时; (3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。 (4)集群运行中可以安全加入和退出一些机器。
p64数据完整性

p65掉线时限参数设置

|